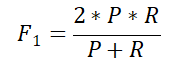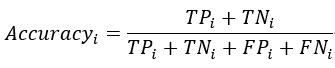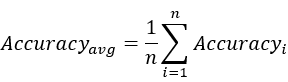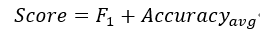任务名称:第二届“小牛杯”幽默计算——情景喜剧笑点识别
一、任务介绍:
幽默是一种特殊的语言表达方式,在日常生活中扮演着化解尴尬、活跃气氛、促进交流的重要角色。而幽默计算是近年来自然语言处理领域的新兴热点之一,其主要研究如何基于计算机技术对幽默进行识别、分类与生成,具有重要的理论和应用价值。
幽默的产生往往依赖于上下文信息,如对话中的幽默通常需要一个铺垫过程,相比于单句幽默,这类幽默的识别更加复杂且困难。在情景喜剧中,部分话语承担了引人发笑的作用,通常称其为笑点(英文为Punchline)。本年度幽默计算任务以情景喜剧为载体,要求参赛者从剧情的对话中识别笑点。
本次评测选取了两部不同语种的情景喜剧(英文为《老友记》,中文为《我爱我家》)作为数据来源。根据场景和剧情的变化,情景喜剧被划分成若干段对话(Dialogue),在一段对话中,存在不同角色进行交流,产生连续的对白(Utterance)。同一段对话中的对白按顺序出现,存在上下文关系。相比于单句幽默,对话中的幽默可能来自于上下文语境,而非对白内容本身。因此,参赛者需要结合上下文语境内容对对白是否幽默作出判断,识别出情景喜剧中的笑点。
二、数据介绍:
本次评测任务的数据涉及两种语言:英文数据来自情景喜剧《老友记》,中文数据来自情景喜剧《我爱我家》。任务根据场景变换将情景剧的对话结构分为Dialogue和Utterance两个层级,其中一个Dialogue包含若干个有序出现的Utterance。
每个Utterance存在幽默标签,标签“0”表示非幽默,“1”表示幽默。英文数据约包含700个Dialogue,10000个Utterance;中文数据包含约500个Dialogue,18000个Utterance。数据集按一定比例划分为训练集和测试集,两者均为csv格式。
数据样例格式如下:
| Field | Type | Description |
|---|---|---|
| id | int | Utterance唯一编号 |
| Dialogue_id | int | 对话编号 |
| Utterance_id | int | 段内对白编号 |
| Sentence | string | 对话文本 |
| Speaker | string | 说话者名称 |
| Label | int | 幽默标签 |
任务数据示例:
| ID | Dialogue_id | Utterance_id | Speaker | Sentence | Label |
|---|---|---|---|---|---|
| 2183 | 53 | 0 | 和平 | 干嘛不承认啊? | 0 |
| 2184 | 53 | 1 | 傅明 | 好啦 不要争啦 | 0 |
| 2185 | 53 | 2 | 傅明 | 这件事情啊,还是由我亲自来问一问小凡 | 0 |
| 2186 | 53 | 3 | 傅明 | 我当年有审问国民党战俘的经验 | 1 |
| 2187 | 53 | 4 | 志国 | 爸 有那么严重么用您把这方面的经验全都用上 | 1 |
| 2188 | 53 | 5 | 傅明 | 怎么没有这么严重啊! | 0 |
| 2189 | 53 | 6 | 傅明 | 我辛辛苦苦养大的女儿 | 0 |
| 2190 | 53 | 7 | 傅明 | 眼看就要离家出走走向深渊冤 | 1 |
| 2191 | 53 | 8 | 傅明 | 冤死我了! | 0 |
| 2234 | 53 | 51 | 傅明 | 这个人呐,看来没有什么问题是学校请来的外国教师肯定是经过有关部门批准的 | 0 |
| 2235 | 53 | 52 | 傅明 | 但是也不能说明这件事情就没有问题 | 1 |
| 2236 | 53 | 53 | 傅明 | 总而言之啊,美国你不能去! | 0 |
上表为中文数据中的一个例子,展示了Dialogue编号为53的整段对话。对话内Utterance编号从0至53,共有54次对白,且其中标签为‘1’的对白为笑点。
| ID | Label |
|---|---|
| id1 | label1 |
| id2 | label2 |
| ... | ... |
五、奖项设置
本评测奖金由小牛翻译独家赞助。由中国中文信息学会计算语言学专委会(CIPS-CL)为获奖队伍提供荣誉证书。
| 奖项 | 一等奖 | 二等奖 | 三等奖 |
|---|---|---|---|
| 数量 | 一名 | 两名 | 三名 |
| 奖励 | ¥10,000 + 荣誉证书 | ¥3,500 + 荣誉证书 | ¥1,000 + 荣誉证书 |
任务数据集发布地址:https://github.com/DUTIR-Emotion-Group/CCL2020-Humor-Computation