第十八届中国计算语言学大会(CCL 2019)技术评测
任务发布
“第十八届中国计算语言学大会” (The Eighteenth China National Conference on Computational Linguistics, CCL 2019)将于2019年10月18日—20日在昆明举行,会议由昆明理工大学承办。大会将组织技术评测任务,为研究者提供测试自然语言处理相关技术、算法和系统的平台。
经过前期评测任务征集与筛选,评测委员会确定了CCL2019的评测任务。本次评测任务设置多样,其中多个任务是首次针对中文设置,具有开创性和探索性。欢迎广大研究者参与评测任务,共同推动相关技术发展。评测任务参与者将被大会邀请参加评测研讨会,进行技术分享。
一、任务简介
任务名称: 第三届“讯飞杯”中文机器阅读理解评测(CMRC 2019)
任务介绍:
第三届“讯飞杯”中文机器阅读理解(CMRC 2019)的任务是句子级填空型阅读理解(Sentence Cloze-Style Machine Reading Comprehension, SC-MRC)。
根据给定的一个叙事篇章以及若干个从篇章中抽取出的句子,参赛者需要建立模型将候选句子精准的填回原篇章中,使之成为完整的一篇文章。 与第一届中文机器阅读理解(CMRC 2017)的填空型阅读理解不同的是:
- 空缺部分不再只是一个词,而是一个句子
- 每个篇章不只是一个空缺,会包含多个空缺位置,机器可利用的信息大大减少
- 最终的测试集中包含假选项,即该选项不属于篇章中任何一个空缺位置,大大增加了解答难度
提醒:所有公开的集合(试验集、训练集、开发集、资格集)均不含假选项
数据介绍:
所有数据请通过官方GitHub目录下载:数据下载地址
| 集合 | 篇章数 | 问题数 | 标注形式 | 是否公开 |
| 试验集(Trial Data) | 139 | 1,504 | 自动标注 | 公开 |
| 训练集(Train Data) | 9,638 | 100,009 | 自动标注 | 公开 |
| 开发集(Development Data) | - | - | 人工标注 | 公开 |
| 资格集(Qualification Data) | - | - | 人工标注 | 半公开 |
| 测试集(Test Data) | - | - | 人工标注 | 隐藏 |
评价方式:
- 问题准确率(Question ACcuracy, QAC):计算问题(一个空即一个问题)级别的准确率
- 篇章准确率(Passage ACcuracy, PAC):计算篇章级别的准确率
基线系统:
我们提供了基于BERT (Chinese, base) 的基线系统:GitHub
注意:若使用BERT相关系统,可[BLANK]替换成BERT词表(vocab.txt)中的[unused],避免被当做unk或被切词切开,具体可参考基线代码实现。
目前仅提供试验集的基线结果,其他集合结果将在对应数据公开(开发集、资格集)或相关比赛节点开始(测试集)后提供。
赛程安排:
| 阶段 | 事件 | 状态 | 时间 |
| 赛前 | 参赛报名 | 已开始 | 即日起 ~ 2019年6月30日(报名截止) |
| 资格赛 | 发布训练集、试验集 | 已开始 | 2019年5月23日 |
| 发布开发集 | 未开始 | 2019年6月10日 | |
| 系统搭建及调整 | 未开始 | 即日起 ~ 2019年7月31日 | |
| 发布资格集,获取决赛资格 | 未开始 | 2019年8月1日 ~ 2019年8月7日 | |
| 决赛 | 提交最终评测系统 | 未开始 | 2019年8月14日 ~ 2019年8月21日 |
| 赛后 | 公布客观结果排名 | 未开始 | 2019年9月(待定) |
| 撰写系统描述报告 | 未开始 | 2019年9月(待定) | |
| 召开CMRC 2019评测研讨会 | 未开始 | 2019年10月19日 |
奖项设置
本届评测将评选出如下奖项,颁发荣誉证书和奖金。
由中国中文信息学会计算语言学专委会(CIPS-CL)为获奖队伍提供荣誉证书。
由科大讯飞股份有限公司和河北省讯飞人工智能研究院为获奖队伍提供奖金。
| 奖项 | 冠军 | 亚军 | 季军 |
|---|---|---|---|
| 数量 | 一名 | 一名 | 三名 |
| 奖励 | ¥20,000 + 荣誉证书 | ¥10,000 + 荣誉证书 | ¥ 5,000 + 荣誉证书 |
任务名称: CCL 中国法研杯相似案例匹配评测竞赛
任务介绍:
本任务是针对多篇法律文书进行相似度的计算和判断。
具体来说,对于每份文书我们提供文书的标题和事实描述,选手需要从两篇候选集文书中找到与询问文书更为相似的一篇文书。
为了减小选手的工作量,我们相似案例匹配的数据只涉及民间借贷这类文书。
数据介绍:
本任务所使用的数据集是来自“中国裁判文书网”公开的法律文书,其中每份数据由三篇法律文书组成。
对于每篇法律文书,我们仅提供事实描述。
对于每份数据,我们用(d, d1, d2)来代表该组数据,其中d,d1,d2均对应某一篇文书。
对于训练数据,我们保证,我们的文书数据d与d1的相似度是大于d与d2的相似度的,即sim(d, d1) > sim(d, d2)。
我们的数据总共涉及三万组文书三元对,所有的文书三元组对都一定属于民间借贷。
评价方式:
对于测试数据,每组测试数据的形式与训练数据一致为(d1, d2, d3)但是此时我们不再保证sim(d, d1) > sim(d, d2)。
选手需要预测最终的结果是sim(d, d1) > sim(d, d2)还是sim(d, d1) < sim(d, d2)。
如果预测正确,那么该测试点选手可以得到1分,否则是0分。
最后选手的成绩为在所有数据上的得分平均值。
更详细的评价方法可以参考https://github.com/thunlp/CAIL2019/tree/master/sc。
基线系统:
我们提供了两组基线模型,包括基于tf-idf的基线模型和基于bert的语言基线模型,你可以在https://github.com/thunlp/CAIL2019/tree/master/sc中找到它们。
赛程安排:
| 赛程阶段 | 初赛阶段 | 复赛阶段 | 封测阶段 | 公布结果 |
|---|---|---|---|---|
| 时间安排 | 2019.5.15—2019.6.09 | 2019.6.10—2019.8.18 | 2019.8.19—2019.9.01 | 2019.9.01—之后 |
奖项设置
挑战赛将评出一等奖1名,二等奖2名,三等奖4名。由主办方中国中文信息学会(CIPS)为获奖者提供荣誉证书认证;由北京幂律智能科技有限责任公司和中国司法大数据研究院为获奖者提供奖励和参会交流赞助。
一等奖20,000 二等奖 10,000 三等奖 5,000
说明:1. 以上所有提及金额均为税前金额。
2. 获奖算法与系统的知识产权归参赛队伍所有,仅要求获奖团队提供算法与系统报告(包括方法说明、数据处理、参考文献和使用开源工具等信息)及团队成员名单,供颁奖会技术交流。
3. 获奖队伍将被邀请在CCL 2019大会举办的技术评测论坛上作技术报告。
任务名称: CCL “小牛杯”中文幽默计算
任务介绍:
幽默是一种特殊的语言表达方式,在日常生活中扮演着化解尴尬、活跃气氛、促进交流的重要角色。而幽默计算是近年来自然语言处理领域的新兴热点之一,其主要研究如何基于计算机技术对幽默进行识别、分类与生成,具有重要的理论和应用价值。
本年度中文幽默计算评测共分为两个子任务:
子任务一:生成幽默识别
幽默生成是幽默计算的重要目标之一,能够赋予计算机人类的沟通技能。该部分工作要求计算机对幽默本质有深入的理解,即理解幽默产生的机制,从而生成具有幽默效果的内容。幽默生成技术的研究将为如聊天机器人等实际应用场景带来更佳的用户体验。因此,本任务旨在通过对幽默产生机制的分析,实现对计算机生成幽默(如例1、例2)的识别,进而作为评估如对话系统、聊天机器人智能性的重要指标。
例1:我想像一个有很多钱的穷人一样生活。
例2:用户友好的计算机首先需要友好的用户
子任务二:中文幽默等级划分
幽默是日常生活中沟通交流的重要组成部分,也是人类智慧与创造力的结晶。由于幽默特征与主观因素关系密切,“可笑或有趣”对于不同的人多具有不同的诠释,即不同的幽默往往存在着不同的幽默等级。为了研究这一现象,该任务旨在通过分析幽默的内容,探索对幽默等级划分有效的方法,即预测不同幽默的有趣程度。本任务对CCL2018中文幽默等级数据集及分类类别进行了扩展,旨在进一步深入挖掘影响幽默等级划分的重要因素。
例3:弱幽默(label=1):忧虑并不能阻止灾难,它会阻止快乐。
例4:普通幽默(label=3):岁寒三友:火锅、白菜、热被窝。
例5:强幽默(label=5):程序员:一种红眼睛,笨拙的哺乳动物,能够与无生命的物体无障碍的交谈。
数据介绍:
子任务一:生成幽默识别
本任务的数据有两部分来源。第一部分是计算机生成幽默,用标签“0”表示。第二部分是非生成幽默,用标签“1”表示。数据集规模近2万条,按比例划分为训练集和测试集,两者均为csv格式。
数据样例格式如下:
| Field | Type | Description |
|---|---|---|
| id | int | 幽默文本ID |
| joke | string | 幽默文本内容 |
| label | int | 幽默文本类型 |
子任务二:中文幽默等级划分
本任务数据在CCL2018中文幽默等级划分数据集的基础上进行了扩展,且新增了一个幽默等级类别,分别用标签“1”、“3”、“5”表示递增的幽默程度。数据集规模近2万条,按比例划分为训练集和测试集,均为csv格式。 数据的样例格式如下:
| Field | Type | Description |
|---|---|---|
| id | int | 幽默文本ID |
| joke | string | 幽默文本内容 |
| label | int | 幽默文本类型 |
两个数据集的规模统计如下:
| 任务 | 子任务一 | 子任务二 |
|---|---|---|
| 训练集 | 16420 | 16670 |
| 测试集 | 4106 | 4171 |
两个任务的数据以及baseline请通过GitHub目录下载: https://github.com/DUTIR-Emotion-Group/CCL2019-Chinese-Humor-Computation
评价方式:
子任务一:生成幽默识别
该子任务是二分类任务,标签有:生成幽默(label=0)、非生成幽默(label=1)。任务采用F1值进行评价,具体公式如下,其中P、R分别代表准确率(Precision)和召回率(Recall):
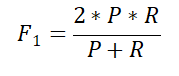
子任务二:中文幽默等级划分
该子任务是三分类任务,标签有:弱幽默(label=1)、普通幽默(label=3)、强幽默(label=5)。任务采用宏平均(Macro-Average)进行评价。宏平均首先对每一个类统计评价指标值,然后对所有类的指标值求算术平均,具体公式如下:
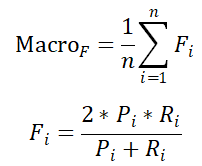 队伍最终的得分由两个子任务的得分综合决定,即:
Score=0.6*子任务一得分+0.4*子任务二得分
队伍最终的得分由两个子任务的得分综合决定,即:
Score=0.6*子任务一得分+0.4*子任务二得分
赛程安排及文件提交:
| 赛程阶段 | 第一阶段 | 第二阶段 | 第三阶段 | 第四阶段 | 第五阶段 |
|---|---|---|---|---|---|
| 截止时间 | 2019.09.08 | 2019.09.15 | 2019.09.22 | 2019.09.29 | 2019.10.06 |
比赛分为5个阶段进行,报名截止时间为2019.09.22 2019.09.15。两个任务取测试集的部分数据(约占测试集数据的25%)构建开发集。比赛的前四个阶段将根据模型在开发集上的得分对参赛队伍排名。完整测试集将在10月5日0点放出,队伍的最终排名由模型在完整测试集上的得分决定。
每个阶段每支队伍在两个任务的开发集(或测试集)上分别仅有一次进行模型效果评测的机会。每个阶段结束之后,我们将在GitHub上更新各个队伍排名及分数。评测的最终结果将在CCL2019官方网站公布。
参赛队伍需要将结果邮件发送至邮箱cn_humor_ccl2019@163.com,邮件的标题为:“CCL2019-参赛队名”,请在邮件的附件中添加结果文件。
两个子任务最终需要提交的结果文件为无BOM的以utf-8为编码格式的csv文件,文件命名格式为:参赛队名_任务名.csv。如:参赛队名为“CCL2019”,提交的文件名为“CCL2019_生成幽默识别.csv”以及“CCL2019_中文幽默等级划分.csv”。
csv文件分隔符使用逗号“,”,每行结尾的换行符为“\n”,提交的结果文件其格式不正确不予计算成绩,其样例格式如下:
| id | label |
| id1 | label1 |
| id2 | label2 |
| ... | ... |
奖项设置
本届评测将评选出如下奖项,颁发奖金和荣誉证书。 本评测奖金由小牛翻译独家赞助。 由中国中文信息学会计算语言学专委会(CIPS-CL)为获奖队伍提供荣誉证书。
| 奖项 | 一等奖 | 二等奖 | 三等奖 |
|---|---|---|---|
| 数量 | 一名 | 两名 | 三名 |
| 奖励 | ¥10,000 + 荣誉证书 | ¥3,500 + 荣誉证书 | ¥1,000 + 荣誉证书 |
注意事项
1.本次评测使用的数据集由大连理工大学信息检索研究室(DUTIR)提供,仅限于本次技术评测使用,未经许可不能作为商业用途或其他目的。 2.训练集数据用于模型的学习,开发集和测试集用于模型的效果评测。其中开发集和测试集的标签信息不公开发布,用于组委会进行最终评测。 3.如需使用本数据集进行课题研究及论文发表,请与DUTIR联系:irlab@dlut.edu.cn。 4.数据集的具体内容、范围、规模及格式以最终发布的真实数据集为准。最终解释权归于CCL2019与DUTIR。 5.仅允许使用所有参赛者均可获得的开源代码、工具以及外部数据。 6.算法与系统的知识产权归参赛队伍所有,要求最终结果排名前6的队伍提供算法代码与系统报告(包括方法说明、数据处理、参考文献和使用开源工具等信息),供会议交流。 7.本评测联系人:杨亮(liang@dlut.edu.cn),张瑾晖(wszjh@mail.dlut.edu.cn)。
二、报名方式
CCL 中国法研杯相似案例匹配评测竞赛:竞赛网站将于2019年05月08日开放注册报名,请及时关注。登录CCL2019中国“法研杯”法律智能挑战赛官网,完善相关信息,即可报名参赛。
第三届“讯飞杯”中文机器阅读理解评测(CMRC 2019):2019/05/23. 评测报名已开启,注册截止时间为6月30日
CCL “小牛杯”中文幽默计算:本次评测采用邮件报名的方式,邮件标题为:“CCL2019-任务名称-参赛单位”,例如:“CCL-中文幽默计算-大连理工大学”;邮件内容为:“参赛队名,参赛队长信息(姓名,邮箱,联系电话),参赛单位名称”。请参加评测的队伍发送报名邮件至相应邮箱:cn_humor_ccl2019@163.com。
| 任务名称 | 报名网址 |
|---|---|
| 第三届“讯飞杯”中文机器阅读理解评测(CMRC 2019) | https://hfl-rc.github.io/cmrc2019/ |
| CCL 中国法研杯相似案例匹配评测竞赛 | http://cail.cipsc.org.cn/instruction.html |
| CCL “小牛杯”中文幽默计算 | 邮箱:cn_humor_ccl2019@163.com |