建设中...
Oral
机器翻译中大规模语料的汉语分词方法
苏晨,张玉洁,郭振,徐金安
Bidirectional Sequence Labeling via Dual Decomposition
Zhiguo Wang, Chengqing Zong and Nianwen Xue
基于表示学习的中文分词算法探索
来思惟,徐立恒,陈玉博,刘康,赵军
Chinese Natural Chunk Research based on Natural Annotations in Massive Scale Corpora ——Exploring Work on Natural Chunk Recognition using Explicit Boundary Indicators
Huang Zhie, Endong Xun, Rao Gaoqi and Yu Dong
一种基于情感句模的文本情感分类方法
陈涛,徐睿峰,吴明芬,刘滨
面向细粒度意见挖掘的情感本体树及自动构建
郭冲,王振宇
基于双语信息和标签传播算法的中文情感词典构建方法
李寿山,李逸薇,黄居仁,苏艳
基于BootStrapping的集成分类器的中文观点句识别方法
吕云云,李旸,王素格
先秦词汇的时代特征自动获取及文献时代的自动判定
刘浏,李斌,曲维光,陈小荷
基于种子词汇的话题标签抽取研究
寇宛秋,李芳
适用于中国外语学习者的英文作文全自动集成评分算法
李霞,刘建达
面向中文专利文献的有标记并列结构的统计分析
石翠,周俏丽,张桂平
基于功能词缀串的维吾尔语词性标注方法
王海波,祖漪清,力提甫·托乎提
基于字符串相似度的维吾尔语中汉语借词识别
米成刚,杨雅婷,周喜,李晓,杨明忠
基于历史模型的蒙古文自动词性标注研究
赵建东,高光来,飞龙
基于中英平行专利语料的短语复述自动抽取研究
李莉,孙茂松,刘知远
基于中文拼音输入法数据的汉语方言词汇自动识别
张燕,张扬,孙茂松
基于特征结构的汉语连动句语义标注研究
陈波,姬东鸿,吕晨
中文事件事实性信息语料库的构建方法
曹媛,朱巧明,李培峰
一种基于情绪表达与情绪认知分离的新型情绪词典
徐睿峰,邹承天,郑燕珍,徐军,桂林,刘滨,王晓龙
基于虚拟上下文的统计机器翻译短语表的过滤
殷乐,张玉洁,徐金安
有限语料汉蒙统计机器翻译调序方法研究
陈雷,李淼,张健,曾伟辉
一种基于分类的平行语料选择方法
王星,涂兆鹏,谢军,吕雅娟,姚建民
iCPE: A Hybrid Data Selection Model for SMT Domain Adaptation
Longyue Wang, Derek F. Wong, Lidia S. Chao, Yi Lu and Junwen Xing
A Kalman Filter Based Human-Computer Interactive Word Segmentation System for Ancient Chinese Texts
Tongfei Chen, Weimeng Zhu, Xueqiang Lv and Junfeng Hu
Chinese Word Segmentation with Character Abstraction
Le Tian, Xipeng Qiu and Xuanjing Huang
A Refined HDP-Based Model for Unsupervised Chinese Word Segmentation
Wenzhe Pei, Dongxu Han and Baobao Chang
Enhancing Chinese Word Segmentation with Character Clustering
Yijia Liu, Wanxiang Che and Ting Liu
基于情绪相关事件上下文的隐含情绪分类方法研究
李寿山,李逸薇,刘欢欢,黄居仁
面向半监督情感分类的特征提取方法研究
王志昊,王中卿,李寿山,李培峰,施寒潇
A Classification-based Approach for Implicit Feature Identification
Lingwei Zeng and Fang Li
Role of Emoticons in Sentence-level Sentiment Classification
Martin Min, Tanya Lee and Ray Hsu
Massive Scientific Paper Mining: Modeling, Design and Implementation
Yang Zhou, Shufan Ji and Ke Xu
基于迭代方法的多层Markov网络信息检索模型
洪欢,王明文,万剑怡,廖亚男
规则与统计相结合的日语时间表达式识别
赵紫玉,徐金安,张玉洁,刘江鸣
基于多步聚类的汉语命名实体识别和歧义消解
李广一,王厚峰
基于图模型的语义角色标注重排序
熊皓,刘群,吕雅娟
联合语义角色标注和指代消解
熊皓,刘群,吕雅娟
基于概念特征的汉语交互类言说动词语义分析及同义词群的构建
肖珊,郭婷婷
基于事件语义特征的中文文本蕴含识别
刘茂福,李妍,姬东鸿
基于中文维基百科的词语语义相关度计算
万富强,吴云芳
基于生成词库论和论元结构理论的语义知识体系研究
袁毓林
“事件”的概念厘定和多维表征
王兴隆
基于深层学习的词义自动归纳
马尔胡甫·曼苏尔,裴文哲,常宝宝
汉语虚词用法在依存句法分析中的应用研究
昝红英,张静杰,娄鑫坡
A New Word Language Model Evaluation Metric For Character Based Languages
Peilu Wang, Ruihua Sun, Hai Zhao and Kai Yu
Automatic Discrimination of Pronunciations of Chinese Retroflex and Dental Affricates
Akemi Hoshino and Akio Yasuda
基于HNC概念关联性的领域判定研究
池哲洁,张全
Power Law for Text Categorization
Wuying Liu, Lin Wang and Mianzhu Yi
Online Distributed Passive-Aggressive Algorithm for Structured Learning
Jiayi Zhao, Xipeng Qiu, Zhao Liu and Xuanjing Huang
应用hLDA进行多文档主题建模关键因素研究
衡伟,于佳,李蕾
Semi-supervised Learning with Transfer Learning
Huiwei Zhou, Yan Zhang, Degen Huang and Lishuang Li
中文篇章级句间语义关系识别
张牧宇,宋原,秦兵,刘挺
篇章标注在医学领域问答系统中的应用
王宇昕,李素建,王荀
交互式问答中基于话语结构的指代消解研究
张超,孔芳,周国栋
Document Oriented Gap Filling Of Definite Null Instantiation in FrameNet
Ning Wang, Ru Li, Zhangzhang Lei, Zhiqiang Wang, and Jingpan Jin
基于句法结构约束的模糊限制信息范围检测
周惠巍,杨欢,黄德根,李瑶,李丽双
基于凸组合核函数的中文领域实体关系抽取
陈鹏,郭剑毅,余正涛,线岩团,严馨,魏斯超
User-Characteristics Topic Mode
Wenfeng Li, Xiaojie Wang and Shaowei Jiang
Learning to Extract Attribute Values from a Search Engine with Few Examples
Xingxing Zhang, Tao Ge and Zhifang Sui
基于对照表以及语义相关性之简繁汉字转换
庞祯军,姚天昉
Poster
Semantic Analysis of Chinese Prepositional Phrases for Patent Machine Translation
Renfen Hu, Yun Zhu and Yaohong Jin
Integrating Multi-source Bilingual Information for Chinese Word Segmentation in Statistical Machine Translation
Wei Chen, Wei Wei, Zhenbiao Chen and Bo Xu
Improving Chinese Word Segmentation Using Partially Annotated Sentences
Kaixu Zhang, Jinsong Su and Changle Zhou
HDP与互信息相结合的中文无指导分词
曹自强,李素建
Spies Hidden in Your Fans: An Effective Approach for Opinion Leader Discovery
Binyang Li, Kam-fai Wong, Lanjun Zhou
基于序列标注模型的情绪原因识别方法
李逸薇,李寿山,黄居仁,高伟
基于多特征融合的中文比较句识别算法
张辰,冯冲,刘全超,师超,黄河燕,周海云
蒙古文输入法输入码方案研究
白双成,张劲松,呼斯勒
基于统计翻译框架的蒙古文自动拼写校对方法
苏传捷,侯宏旭,杨萍,员华瑞
“把”字句的自动释义与句式变换研究
王璐璐,孙薇薇,袁毓林
基于语言模型解答大学生英语四级测试多选填空的实验性研究
范志航,林睿,杨沐昀,李生,赵铁军
中文短文本去重方法研究
高翔,李兵
Automatic Discrimination of Pronunciations of Chinese Retroflex and Dental Affricates
Akemi Hoshino and Akio Yasuda
融合音节特征的最大熵藏文词性标注研究
于洪志,李亚超,汪昆,冷本扎西
维哈柯及蒙语多文种语言相似性考查研究
达瓦·伊德木草,艾尼宛尔·托乎提,于清,吾守尔·斯拉木
基于机器翻译的跨语言关系抽取
胡亚楠,舒佳根,钱龙华,朱巧明
维吾尔语多词表达抽取方法研究
麦热哈巴·艾力,阿孜古丽·夏力甫,吐尔根·依布拉音
傣文自动分词系统的设计与实现
高廷丽,戴红亮
蒙古语熟语资源库的初步构建
海银花,那顺乌日图,额尔敦朝鲁
基于条件随机场的藏文人名识别研究
康才畯,龙从军,江荻
面向信息检索的藏文文本索引策略研究
万福成,何向真,夏建华,杜玉祥
基于规则的哈萨克语动词短语识别研究
古丽拉·阿东别克,古丽扎达·海沙
新闻语料中中日命名实体词汇翻译的自动抽取
尹存燕,黄书剑,戴新宇,陈家骏
中小学维吾尔语教材用词数据分析方法与应用研究
艾孜尔古丽,李晓,玉素甫.艾白都拉
多语料库中汉语四字格的切分和识别研究
徐润华,曲维光,陈小荷,王东波
基于词对依存分类的藏语树库半自动构建研究
华却才让,姜文斌,赵海兴,刘群
基于新闻语料库的越南语框架语义研究
林丽
上古汉语分词及词性标注语料库的构建——以《淮南子》为范例
留金腾,宋彦,夏飞
基于事件语义距离的V1-V2述结式判别研究
马腾,詹卫东
基于强制对齐的层次短语模型过滤和优化
付晓寅,魏玮,卢世祥,徐波
汉英篇章结构平行语料库的对齐标注研究
冯文贺
Graphic Language Model for Agglutinative Languages: Uyghur as Study Case
Miliwan Xuehelaiti, Kai Liu, Wenbin Jiang and Tuergen Yibulayin
Multi-Classifier Combination for Translation Error Detection
Jinhua Du, Junbo Guo, Sha Wang and Xiyuan Zhang
面向短语统计机器翻译的汉日联合分词研究
吴培昊,徐金安,张玉洁
汉英机器翻译中格式转换研究
刘智颖,郭艳波,晋耀红
Development of Traditional Mongolian Dependency Treebank
Xiangdong Su, Guanglai Gao and Xueliang
Chinese Sentence Compression: Corpus and Evaluation
Chunliang Zhang, Minghan Hu, Tong Xiao, Jingbo Zhu, Xue Jiang and Lixin Shi
个性化知识的表示方法
刘冬明,杨尔弘
基于句式结构的汉语图解析句法设计
彭炜明,宋继华,王宁
基于混合策略的汉语最长名词短语识别
钱小飞,侯敏
基于自动编码器的中文词汇特征无监督学习
张开旭,周昌乐
韩国语名词短结构特征分析及自动提取
安帅飞,毕玉德
藏语句法功能组块的边界识别
李琳,龙从军,江荻
评价短语的倾向性分析研究
侯敏,滕永林,陈毓麒
基于属性融合的微博用户分类模型
尹杰,张绍武,林鸿飞,魏现辉,刘晓霞
Emotional McGurk Effect? A Cross-Cultural Investigation on Emotion Expression under Vocal and Facial Conflict
Aijun Li, yuan Jia and Qiang Fang
Mining User Preferences for Recommendation: a Competition Perspective
Shaowei Jiang, Xiaojie Wang, Caixia Yuan and wenfeng li
Interactive Question Answering Based on FAQ
Song Liu, Yixin Zhong and Fuji Ren
年度新词语使用的时空分布考察
杨尔弘
基于图的查询日志实体别名抽取方法
石贝,孙乐,韩先培
Natural Language Understanding for Grading Essay Questions in Persian Language
Iman Mokhtari-Fard
“对象格”语义范畴及其相关语义角色的自动识别研究
汪梦翔,王厚峰
基于CCMO的现代汉语介词词义结构描写
邱庆山
基于语义关系图的词汇语义相关度计算研究
李佳媛,张仰森
现代汉语常用动词释义对比研究 --以《现代汉语词典》(第六版)和《“台湾教育部”教育部重编国语辞典(修订本)》为例
刘珺,徐德宽,陈淑梅
Exploiting Lexicalized Statistical Patterns in Chinese Linguistic Analysis
Yu Zhao and Maosong Sun
汉语自然话语的音高下倾
王茂林,訾广玲
歧义结构理解中的依存距离最小化倾向
赵怿怡,刘海涛
Interesting Linguistic Features in Coreference Annotation of an Inflectional Language
Maciej Ogrodniczuk, Katarzyna Głowińska, Mateusz Kope, Agata Savary and Magdalena Zawisławska
基于分词与词性标注的汉语逗号自动分类
古晶晶,周国栋
基于细粒度特征的话题句识别方法
蒋玉茹,宋柔
基于广义话题结构语料库的报告语体与小说语体对比研究
尚英,宋柔
基于LDA模型和SVM方法的微博用户性别判别
孙世杰,李珠峰,濮建忠
基于层次聚类的跨文本中文人名消歧研究
张菲菲,李宗海,周晓辉,李晓戈
一种抽取微博关键短语的网络图模型
黄河燕,廖黎姿,王亚珅,魏骁驰
微博语言的复杂网络特征研究
马宏炜,陆蓓,谌志群,黄孝喜,王荣波
基于中英文网络安全应用本体的跨语言信息检索研究
张飞,毕玉德
中国中文信息学会2013年学术年会(CIPS 2013)暨
第十二届全国计算语言学会议(CCL 2013)正式通知
尊敬的各位会议代表:大家好!
经中国中文信息学会第7届理事会第6次理事长办公会讨论决定,中国中文信息学会学术年会暨理事会(CIPS 2013)于2013年10月9日在苏州大学召开。中文信息处理(包括对汉语以及少数民族语言的信息处理)在我国信息领域科学技术发展与产业发展中占有重要的位置。计算机和互联网技术的不断发展对中文信息处理技术提出了新的挑战。中文信息处理已经成为信息科学技术中长期发展的一个新的战略制高点。本次学术年会将是我国中文信息处理领域广大专家学者(约300人)的一次盛会,将有力促进中文信息处理领域的理论创新、技术交流与产学研合作!我们诚挚邀请大家参与中国中文信息学会2013年学术年会,一起分享,共同探讨,努力促进我国中文信息处理领域的技术与产业的创新与发展!本次会议的主题是:深度学习与中文信息处理,我们将邀请顶级专家做特邀报告,并开展相关主题的研讨。
"第十二届全国计算语言学会议"(The Twelfth China National Conference on Computational Linguistics, CCL 2013)将于2013年10月10日—12日在苏州大学举行。作为国内最大的自然语言处理专家学者的社团组织——中国中文信息学会(CIPS)的旗舰会议,全国计算语言学会议从1991年开始每两年举办一次。CCL着重于中国境内各类语言(如汉语、藏语、蒙古语以及维吾尔语等)的计算处理,为传播计算语言学最新的学术和技术成果提供了广泛的交流平台。同时,"第一届基于自然标注大数据的自然语言处理国际学术研讨会"(NLP-NABD 2013)将与CCL 2013联合召开。NLP-NABD特别关注在大数据时代自然语言处理的前沿方法和技术,将聚焦国内外基于自然标注大数据方向上的各种前沿研究进展,包括:如何在自然标注大数据上有效进行大规模无监督/半监督机器学习(如深度学习),如何将学习到的资源、模型和已有的手工标注的核心资源和核心语言计算模型结合起来。
本次会议期间,中国中文信息学会还将举办第一届中文知识图谱研讨会(The 1st Conference on Chinese Knowledge Graph)。知识图谱(Knowledge Graph)是当前学术界和企业界的研究热点。中文知识图谱的构建对中文信息处理和中文信息检索具有重要的价值。本次知识图谱研讨会将着重探讨中文知识图谱的构建的资源、技术、方案、策略以及待研究问题和挑战,促进研究单位之间以及研究界和产业界之间的学术交流,探索今后大规模中文知识图谱构建的研讨与合作机制。目前为止,大会已经得到国内自然语言处理研究者的广泛关注,目前有约10家从事知识图谱研究和实践的著名高校、研究机构和企业的专家及学者有意参与并发表演讲。
现将会议正式通知和会议回执寄上,请您按通知上的时间到指定地点报到并参加会议。
一.会议时间:
1. 中国中文信息学会学术年会(CIPS 2013): |
| 报到时间:2013年10月8日 14:00开始 |
| 召开时间:2013年10月9日(会期一天) |
2. 计算语言学会议(CCL 2013 & NLP-NABD 2013): |
| 报到时间:2013年10月9日 8:00开始 |
| 召开时间: 2013年10月10日至11日(会期两天) |
3. 中文知识图谱研讨会: |
| 报到时间:2013年10月11日 14:00开始 |
| 召开时间:2013年10月12日 上午(会期半天) |
| 会议报到地点: 苏州凯莱大酒店CCL 2013会议会务组 |
二.会议住宿地点:苏州凯莱大酒店及东吴饭店(校外,离会场600米),会议代表食宿自理,住宿收费标准见回执
(回执下载在本页尾处)。
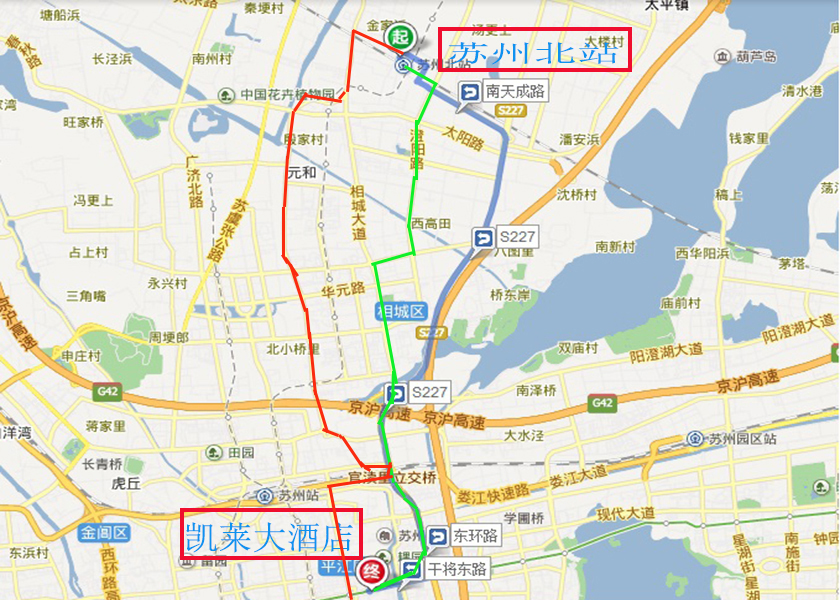
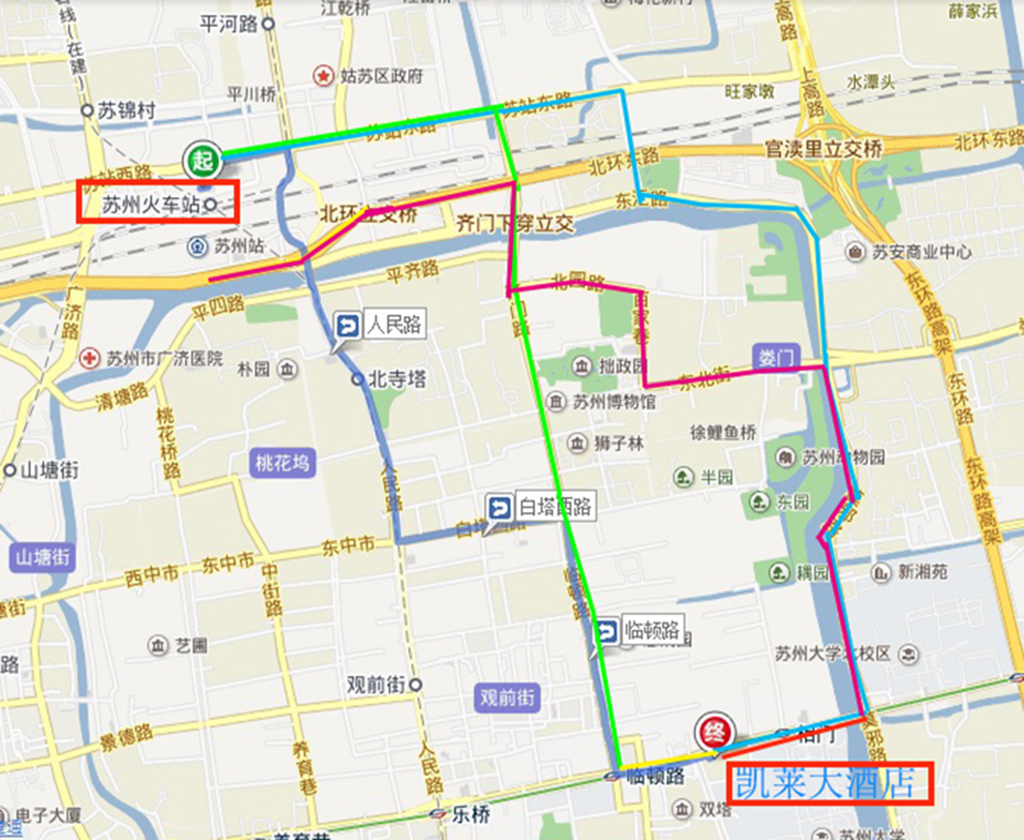
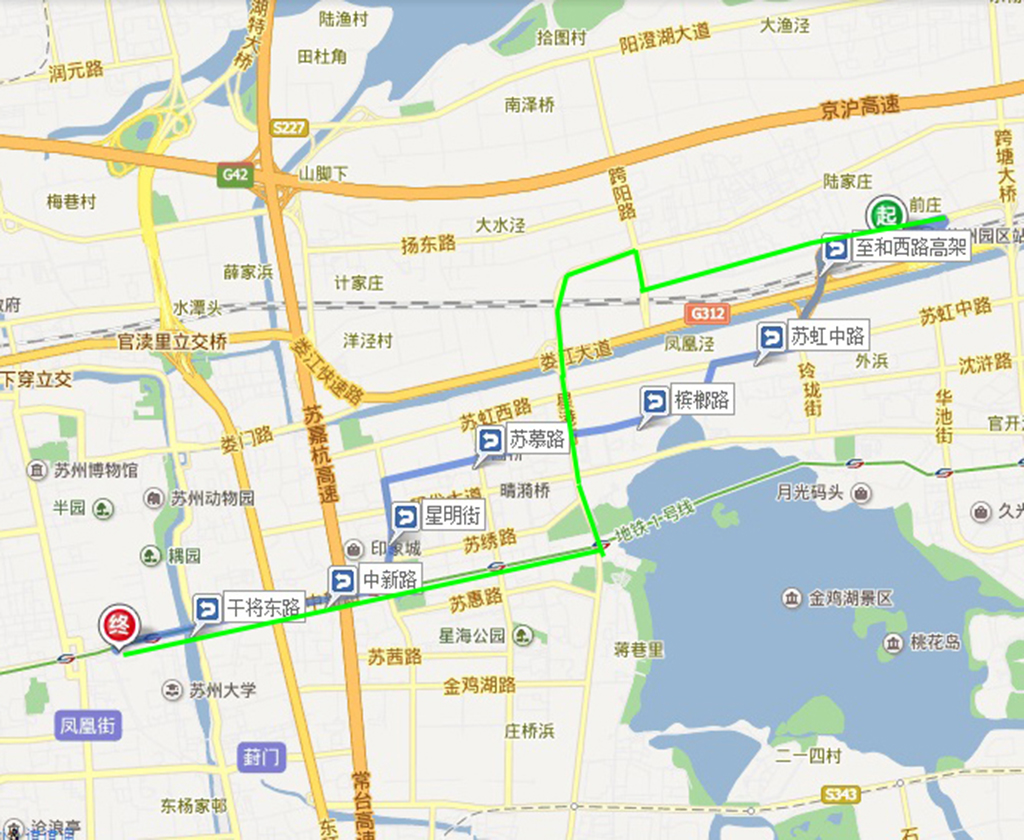
三.参加各会议的代表们请自行到达凯莱大酒店(会议注册地点)报道
(交通路线见本网站的参会说明-交通路线)。
四.会议注册费情况:
| 1.基本费用(适用于会员): |
| 中文信息学会学术年会:理事(1000元/人),非理事(500元/人) |
| 计算语言学会议:1000元/人 |
| 知识图谱研讨会:500元/人 |
| 2.学生会议代表在上述费用的情况下,每个会议优惠200元。 |
| 3.会议代表如同时参加两个会议,注册费总额优惠100元,同时参加三个会议优惠200元。 |
| 4.非中文信息学会会员的会议代表在上述费用的基础上,每个会议的注册费增加200元。 |
| 5.9月20日之后或现场交费的会议代表,每个会议的注册费增加200元。 |
五.会议注册费可通过下列方式支付:
| 1.银行转账。户名:中国中文信息学会。开户行:工商行北京市分行海淀西区支行。账号:0200004509014415619。 |
| 2.邮局汇款。收款人:中国中文信息学会。地址:北京8718信箱"中国中文信息学会"。邮编:100190。电话:010-62562916。 |
| 3.直接交费。收款人:中国中文信息学会。地址:北京海淀区中关村南四街4号院7号楼201房间。电话:010-62562916。 |
| 4.现场交费。苏州凯莱大酒店接待大厅会务组收费处。 |
注意:请在转账(汇款)备注中注明“姓名(参加会议编号)”,如“张三(1+2+3)”;多人一起转账汇款请分别注明姓名,如“张三,李四,王五(1+2+3)”,或分别注明参加的会议编号。
六.每篇被正式录用的会议论文必须至少有一名作者注册计算语言学会议(CCL 2013 & NLP-NABD 2013),否则论文不予发表。有关论文版面费的情况,由组委会另行通知。
七.请认真填好会议回执, 将自己所要预定的房间种类和住宿起止日期写清楚。由于会议期间住宿紧张,会议回执请务必在9月15日之前发送至会务组邮箱:CCL2013@suda.edu.cn;不住宿的代表也要寄回回执。请详细填写每项信息,以便会务组准备资料、通讯录、代表证卡等。收到回执后,会务组会及时返回确认邮件。若未收到确认邮件,请电话联系会务组。
八.联系方法:
| 钱龙华:133-0620-8165 | qianlonghua@suda.edu.cn |
| 王红玲:138-6240-9198 | hlwang@suda.edu.cn |
| 洪 宇:133-7519-7289 | hongy@suda.edu.cn |
九.请注意此页尾有会议回执下载。
顺致敬礼并祝一切安好!
中国中文信息学会
2013年8月31日
会议回执下载处
CIPS2013 & CCL2013 会议回执
特邀讲座嘉宾

李德毅
中国电子系统工程研究所
题目:大数据时代的认知计算.
摘要:长期以来,认知科学一直在困境中挣扎。如何用科学的方法研究思维和意识?人的意识和精神活动是由神经细胞、胶质细胞的行为和构成方式、以及影响它们的原子、离子和分子性质所决定的吗?是由物理和化学规律支配的吗?是由大脑不同区域共同作用产生的吗? 至今,人们对大脑的功能和运作机制的复杂性仍然很无知,不能解决人的思维和意识问题。 但另一方面,人类已经进入大数据时代,在半个世纪经久不息的全球人机棋类大赛中,机器和网络表现出非凡的计算智能;移动互联网支撑大数据发现价值,导致在线的机器翻译、云搜索、语音识别和合成,语音和文字自然转换、统计学习等自然语言理解的成功运用,正在猛烈地改变着我们的日常生活;智能车模拟驾驶员在驾驶活动中的视听觉认知计算,甚至被称作汽车的颠覆性创造。总之,认知计算的丰富实践正在倒逼认知科学的研究!我们愿意结合我们长期以来提出的定性定量转换的双向认知模型——云模型,探索如何迎接数据密集型认知科学的革命。
简历:计算机工程和人工智能专家,中国工程院院士,欧亚科学院院士,现任或曾任中国指挥与控制学会名誉理事长,中国人工智能学会理事长,国家信息化专家咨询委员会委员,全军战略规划咨询委员会委员,总装科技委兼职委员,总参信息化部研究员,博士生导师,清华大学、国防大学兼职教授。

王海峰
百度
题目:互联网大数据、深度学习与自然语言处理.
摘要: 无论是按广为人知的4个“V”的定义,还是其它各种流派的定义,互联网数据都是一种真正意义上的大数据。虽然互联网上各种类型的数据日趋丰富,但语言文字仍是互联网内容的主要载体、也是互联网用户表达需求的主要形式。因而,自然语言处理也仍然在互联网技术产品中扮演着至关重要的角色。无论是传统的词法、句法、语义分析,还是近来大热的知识图谱、深度问答、智能交互,都在互联网上有着广泛的应用。深度学习首先在语音识别、文字识别、图像处理等领域证明了其价值,而近来,它在自然语言处理技术中也开始产生作用。本报告将围绕互联网大数据、深度学习与自然语言处理展开讨论。
简历:王海峰,博士,现任百度首席科学家(基础技术),兼任北京大学语言信息工程系主任、哈尔滨工业大学兼职教授、博士生导师、全国信息技术标准化技术委员会委员、国家核高基重大专项总体专家组成员等。在国际学术界,王海峰是自然语言处理领域世界上影响力最大、也最具活力的国际学术组织ACL(Association for Computational Linguistics)50年历史上唯一华人主席,他还曾担任或正在担任国际期刊副编辑、客座编辑、顶级国际会议的程序委员会主席、Workshop主席、Tutorial主席、Industry track主席、及领域主席等。王海峰1999年3月毕业于哈尔滨工业大学获,博士学位,曾任微软中国研究院副研究员、isilk.com 研究科学家(香港特区政府优秀人才计划),东芝(中国)研究开发中心副所长兼研究部部长、首席研究员等。
吴华,博士,现任百度高级科学家,百度自然语言处理技术负责人。加盟百度前,曾任微软(亚洲)研究院副研究员、东芝(中国)研究开发中心主任研究员、研究经理。主要研究领域包括机器翻译、自然语言处理、机器学习等。吴华将担任NLP领域排名第一的国际会议ACL 2014的程序委员会主席,并曾担任IJCNLP 2011、ACL 2012领域主席。

任福继
日本德岛大学
题目:语言理解、情感机器人、心理健康计算.
摘要:人工智能奠基人之一的Minsky指出:问题不在于智能机器是否能有情感,而在于没有情感的机器怎么能是智能的?此说法已获得了人们的广泛共识。随后的研究发现:大脑中情感通道受损的患者的认知能力和智商并没有降低,而做决策的能力却严重受损。由此可见,情感是智能的一部分,是智能不可分割的要素;先进智能(指自然智能与人工智能的高度融合)要取得突破,在很大程度上取决于我们能否赋予机器具有情感能力,包括情感认知和情感合成能力。本报告着重阐述基于语言理解的情感计算方法,建立在语言声音表情等多模态基础上的情感机器人构建原理,运用心状态转移网络及先进智能理论对心理健康进行感知与计算的理论及工程手法。
简历:任福继,日本国立北海道大学工学博士。曾先后任职于日本CSK主任研究员、美国新墨西哥州立大学访问教授、日本国立德岛大学教授、美国佛罗里达国际大学客座教授、日本国立德岛大学智能工程系主任、信息决策部门长、国际连携教育开发中心副中心长。中国科学院海外评审专家、海外杰出青年学者基金获得者、中国科学技术协会海智专家、教育部长江学者讲座教授。IEEE自然语言处理与知识工程国际会议创立者、会议主席。在日中国科学技术者联盟首届会长、日本新华侨华人会前会长及名誉会长、全日本中国人博士协会原会长。日本信息处理学会、人工智能学会、语言处理学会、电子信息通信学会及IEEE高级会员,亚洲太平洋机器翻译协会会员,美国ACL、IASTED会员。日本工程会院士。中国人工智能学会副理事长。日本自然科学源内赏、康乐会奖、吴文俊人工智能科学技术奖创新一等奖获得者.

Randy Goebel
加拿大阿尔伯特大学
题目:Natural Language Processing: The Challenge of Compressing Data to Models.
摘要:The problem of machine processing of natural language (NLP) has long been a research focus of artificial intelligence. This is partly because the use of natural language is easily conceived as a cognitive task requiring human-like intelligence. It is also because the rational structures for computer interpretation of language require the full suite of computational tools developed over the last hundred years (grammar, dictionaries, logic, parsing, inference, and context management). Most of the recent practical advances in NLP have arisen in the context of simple machine learning applied to large language corpora, to induce fragments of language models that provide the basis for interpretive and generative manipulation of language. These largely statistical models are arisen in what has been called the "pendulum swing" of NLP, in which statistical models have recently dominated those based on structural linguistics. In this lecture, we look at the concept of noisy corpora and their role in language models, including some interesting alternative sources of data for building language models. The applications range from complex language summary to the information extraction from medical, legal, and historical documents.
简历:Randy Goebel is a professor in the department of Computing Science at the University of Alberta, in Edmonton, Alberta, Canada.
He is also vice president of the innovates Centre of Research Excellence (iCORE) at Alberta Innovates Technology Futures (AITF: www.albertainnovates.ca), chair of the Alberta Innovates Academy, and principle investigator in the Alberta Innovates Centre for Machine Learning (www.aicml.ca). He received the B.Sc. (Computer Science), M.Sc. (Computing Science), and Ph.D. (Computer Science) from the Universities of Regina, Alberta, and British Columbia, respectively.
At AITF, Randy is in charge of reshaping research investments (graduate student scholarships, research chairs, research centres). His research interests include applications of machine learning to systems biology, visualization, and web mining, as well as work on natural language processing, web semantics, and belief revision. Randy has experience working on industrial research projects in crew scheduling, pipeline scheduling, and steel mill scheduling, as well as scheduling and optimization projects for the energy industry in Alberta.
Randy has held appointments at the University of Waterloo, University of Tokyo, Multimedia University (Malaysia), Hokkaido University (Sapporo), and has had research collaborations with DFKI (German Research Centre for Artificial Intelligence), NICTA (National ICT Australia), RWC (Real World Computing project, Japan), ICOT (Institute for New Generation Computing, Japan), NII (National Institute for Informatics, Tokyo), and is actively involved in academic and industrial collaborative research projects in Canada, Australia, Europe, and China.

林德康
美国Google公司
题目:Mining Lexical Knowledge from Unlabeled Text.
摘要:There has been a great deal work on acquiring lexical knowledge from unlabeled text, by using textual patterns to extract properties of words or phrases or relationships between them. Many types of lexical knowledge can be obtained this way, including the gender and animacy properties of words, type-instance relationships, part-of relationships, etc. In this talk, I will discuss several examples of this approach and address a number of related issues, such as ``What constitute good patterns?'', ``Where do they come from?'' and 'How to deal with the inherent noise in the extracted instances?''
简历:Dekang Lin is a Staff Research Scientist at Google. Dekang Lin received his BSc from Tsinghua University and his PhD from the University of Alberta, both in Computer Science. Before joining Google in 2004, he was a professor at the University of Alberta. His main research interests include principle-based parsing and unsupervised learning from text and question-answering. He is Co-Editor-In-Chief of the Transactions of the Association for Computational Linguistics and was General Chair for ACL 2013 and Program Co-chair for ACL 2002.

邓力
美国微软研究院
题目:Deep Learning: From Academic Concepts to Industrial Triumph.
摘要:Deep learning is a sub-field of machine learning that focuses on hierarchical representations of features or concepts, where high-level semantic-like features can emerge via automatic layer-by-layer learning from low-level features. In recent years, deep learning has achieved important successes in a variety of applied artificial intelligence tasks including speech recognition, computer vision, and natural language processing. The implications of such recent work have been prominently covered in recent media (e.g., NYT, Economist, MIT Technology Reviews, Google acquisition of DNNResearch, etc.). Since 2009, in partnership with leading academic researchers, Microsoft Research has been pursuing deep learning research and technology transfer, and has pioneered the development of industry-scale deep learning technology for speech recognition and other applications, resulting in industry-wide adoption of deep learning in Windows Phones (Microsoft), Android Phones (Google), iPhones (Siri of Apple and Nuance/IBM), and Baidu Phones. In this lecture, I will provide a historical overview on how academic conceptualization of deep learning rapidly evolved into wide product deployment worldwide within only a few short years, and discuss what implications this recent triumphant history may have for future academic-industrial collaborations. I will also go into some technical depth in describing the current deep learning technology, and in particular the disparate approaches which industry and academia take in current pursuits of the technology. I will conclude by analyzing future directions of deep learning, and speculating on what types of information processing and artificial intelligence applications may benefit most from deep learning technology in light of the known mechanisms of human brain that grounds intelligence and extreme effectiveness in information processing.
简历:Li Deng received the Ph.D. degree from the University of Wisconsin-Madison. He was an assistant professor (1989-1992), tenured associate professor (1992-1996), and Full Professor (1996-1999) at the University of Waterloo, Ontario, Canada. In 1999, he joined Microsoft Research, Redmond, WA, where he is currently a Principal Researcher. Prior to MSR, he also worked or taught at Massachusetts Institute of Technology, ATR Interpreting Telecom. Research Lab. (Kyoto, Japan), and HKUST. He has been granted over 60 US or international patents in acoustics/audio, speech/language technology, and machine learning. He received numerous awards/honors bestowed by IEEE, ISCA, ASA, and Microsoft. In the general areas of audio/speech/language technology and science, machine learning, and signal/information processing, he has published over 300 refereed papers in leading journals and conferences and 4 books. He is a Fellow of the Acoustical Society of America (ASA), a Fellow of the IEEE, and a Fellow of the International Speech Communication Association (ISCA). He served on the Board of Governors of the IEEE Signal Processing Society (2008-2010), and as Editor-in-Chief for the IEEE Signal Processing Magazine (2009-2011). He serves as General Chair of the IEEE ICASSP-2013, and as Editor-in-Chief for the IEEE/ACM Transactions on Audio, Speech and Language Processing. He initiated the deep learning work within Microsoft in 2009 (working with Prof. Geoff Hinton “in house”), with its inspiration and influence soon spread to the industry. His technical work and the leadership since 2009 in industry-scale deep learning with colleagues and academic collaborators have created significant impact in speech recognition and the related areas of information processing including information retrieval, spoken language understanding, speech synthesis, image recognition, machine translation, and web search.

季姮
Computer Science Department
题目:Mining Lexical Knowledge from Unlabeled Text.
摘要:Recent years have witnessed a big data boom that includes a wide spectrum of heterogeneous unstructured data types, from image, speech, and multimedia signals to text documents. Information Extraction (IE) is a task of identifying “facts”, such as the attack/arrest events, people's jobs, people's whereabouts, merger and acquisition activity from such unstructured data sets on a massive scale. Traditional IE techniques assess the ability to extract information from individual documents in isolation. However, users need to gather information which may be scattered among a variety of sources. These facts may be redundant, complementary, incorrect or ambiguously worded. Furthermore, the extracted information from a document may need to augment an existing Knowledge Base (KB). This requires the ability to link events, entities and associated relations in a document to KB entries and thus present many unique challenges. In this talk, I will define several new extensions to state-of-the-art IE and systematically present the foundation, methodologies, algorithms, and implementations needed to create the next generation of information access with more accurate and robust extraction capabilities. More specifically, I will discuss: (1). How to break the performance ceiling of IE by changing the fundamental philosophy from sequential pipeline to joint modeling? (2). How to decode and encode information morphs from noisy data under active censorship? (3). How to construct and populate a trustable KB by marrying IE with data mining?
简历:Heng Ji is the Edward G. Hamilton Development Chair Associate Professor in Computer Science Department of Rensselaer Polytechnic Institute (RPI). She is a faculty member affiliated with three research centers at RPI: Tetherless World Constellation, Rensselaer Institute for Data Exploration and Applications, and Center for Cognition, Communication & Culture. She received her B.A. and M.A. in Computational Linguistics from Tsinghua University in 2000 and 2002 respectively; and her M.S. and Ph.D. in Computer Science from New York University in 2005 and 2007 respectively. Her research interests focus on Natural Language Processing, especially on Cross-source Information Extraction and Knowledge Base Population (KBP). She received Google Research Award, NSF CAREER award, Sloan Junior Faculty award, IBM Watson Faculty award, PACLIC2012 Best Paper Runner-up, "Best of SDM2013" Paper award and AI's Top 10 to Watch award by IEEE Intelligent Systems. She co-organized the NIST TAC-KBP track in 2010 and 2011, and served as the Information Extraction area chair for NAACL2012, ACL2013 and EMNLP2013. Her research is funded by NSF, ARL, DARPA, Google and IBM.